Rpm、Yum(程序包管理)
一、前言
对于普通用户来说,安装一个程序,都可以比较简单的通过双击鼠标或者一条命令就可以完成,但如果没有包管理器,一切操作由用户自行完成,那么过程大概需要下载源码、编译、汇编、链接、将各类配置文件分门别类的存放,过程中需要人为指定大量参数,才能保证日后运行时某些需要的特性可以使用,并且用户也需要清楚的知道安装进度到了哪一步。这还仅仅是安装,那么日后的卸载呢?更新呢?人为操作步骤繁琐不说,出错的几率也非常大。所以就出现了包管理器,它可以将安装步骤简化到仅用一条命令,并且还将各类配置文件分发到正确路径,日后更新或者删除还可以准确的追踪每一个文件。
二、RPM包管理器
由红帽开发,全称为RPM is Package Manager
1. 命名方式
任何一个rpm包都是由它人拿到源代码编译制作的,所以rpm包命名方式和源码包相关
- 源码包的命名方式:
name-VERSION.tar.gz
version由三部分组成:major.minor.release,也就是主版本号.次版本号.发行号 - rpm包的命名方式:
name-VERSION-ARCH.rpm
version:同样继承源码包的major.minor.release
ARCH由三部分组成:release.os.arch,这里的release为rpm的编译版本
示例:
- 源码包名称:
zlib-1.2.7.tar.gz - rpm包名称:
zlib-1.2.7-13.el7.i686.rpm
2. 拆包的概念
如果一个程序包可以提供十种功能,大部分人都只用其中的五种,而一小部分人需要用到全部的功能,那么编译的时候就可以将一个包拆成多个包发行,让用户自行选择安装,这样不但可以节约空间,更重要的是,也免受未安装功能的漏洞侵害
3. 一个程序包的构成
- 文件清单:记录这个程序包中的文件清单
- 安装或卸载时运行的脚本:程序包安装或卸载时需要完成的预先配置工作或卸载后配置工作,都记录在这些脚本中
4. 包管理器数据库
4.1 功用
- 记录每个程序包的名称及版本
- 程序包的依赖关系
- 程序包的功能性说明
- 安装生成的歌文件路径及每个文件的校验码信息
4.2 管理相关
- 路径:
/var/lib/rpm - 初始化或重建:
rpm {--initdb|--rebuilddb},通过读取每个程序包的元数据信息完成重建
--initdb:如果事先不存在,则新建,否则不执行任何操作
--rebuilddb:无论存在与否,直接重新创建数据库
5. 获取程序包的途径
- 系统发行版的安装光盘或官方发行版服务器,光盘中的程序包是一般都是经过充分市场验证的包,但是时效性较差,而发行版的官方服务器访问速度较差,可以访问国内的镜像服务器,如阿里镜像:
http://mirrors.aliyun.com、sohu镜像:http://mirrors.sohu.com网易镜像:http://mirrors.163.com - 项目官方:前往某个项目的官方服务器
- 第三方组织的服务器:Fedora-EPEL、http://pkgs.org http://rpmfind.net http://rpm.pbone.net
- 自行制作
6. 命令格式
安装命令格式:rpm {-i|--install} [install-options] PACKAGE_FILE ...
|
|
升级命令格式
rpm {-U|--upgrade} [install-options] PACKAGE_FILE ...:如果安装有旧版程序包,则升级,如果指定不存在旧版程序包则安装rpm {-F|--freshen} [install-options] PACKAGE_FILE ...:安装有旧版程序包则升级,如果不存在旧版程序包,则不执行操作
|
tips:
- 不要对内核做升级操作:linux内核4.0之前的内核升级完成都需要重新启动,如果升级失败了,重启根本无法完成。幸好linux支持多内核版本并存,所以直接安装新版本内核即可
- 如果源程序包的配置文件安装 后曾被修改,升级时,新版本提供的同一个配置文件不会直接覆盖老版本的配置文件,而把新版本的文件重命名为
FILENAME.rpmnew后保留
查询命令格式:rpm {-q|--query} [select-options] [query-options]
|
|
卸载命令格式:rpm -e [--allmatches] [--justdb] [--nodeps] [--noscripts] [--notriggers] [--test] PACKAGE_NAME ...
|
校验命令格式:rpm {-V|--verify} [select-options] [verify-options]
此命令是用来校验以生成的文件与程序包数据库中的留存信息,这样就可以确定那个文件发生修改了,校验的内容包括文件的大小、权限、属主、属组等信息
|
|
7. 程序包的来源合法性及完整性验证
互联网中的很多程序包都是个人制作,为了避免被内置很多后门,所以尽量选项目官方站点或项目站点下载程序包。不过,即便是从官方站点的下载的程序包,也有可能在传输过程中被篡改,所以验证包的来源合法性及完整性就尤为重要,可以使用命令导入官方提供的公钥信息进行验证。比如安装光盘中的,就有验证光盘中的程序包的公钥。
- 导入公钥的命令:
rpm --import /path/to/pubfile
三、 yum
由yellow dog研发,全称为Yellowdog Update Modifier
1. 配置文件
/etc/yum.conf:为所有仓库提供配置公共配置
|
/etc/yum.repo.d/*.repo:为仓库的指向提供配置
|
- 配置文件中的变量
|
2. 命令
命令格式:yum [options] [command] [package ...]
|
|
四、程序包的编译安装
1. 程序为什么需要编译
你有没有想过我们只是想简单的运行一个程序,为什么需要这么繁琐,什么预处理、编译、汇编、链接之类的操作。比如我想运行Nginx,那么你直接给我一个nginx的程序,复制过去就能运行不就得了,整那么多干嘛?要想解释清楚这个问题,那么就需要扯的比较远了。下面我试着将这个问题讲清楚。
结合下图,一层一层的说,从下至上:
- 硬件:我曾经看过一本书《穿越计算机的迷雾》(不过没读完),里面阐述了计算机为什么要用二进制、如何通过逻辑门(与门、或门、非门、同或门、异或门等)实现加减乘除计算。从宏观角度看一颗cpu,上面的一个针脚就是一个逻辑门,通过控制各种组合的针脚通电、放电来完成计算工作。那么问题就是,虽然它们都可以完成计算操作,但是不同厂商计算逻辑肯定是不同的,比如A说我们针脚1通电表示1,B说我们针脚2通电表示1,并且这些计算逻辑因为是商业机密的原因,肯定也不可能互相分享。这些通电放电的操作我们称之为指令集,想调用的必须通过二进制指令调用(叫做硬件规格或机器语言),但是对于大多数人来说,0101010的代码无异于天书,于是在cpu生产完成后,都会由厂商附加一套略微高级的调用接口,我们称之为微码编程接口或汇编语言,汇编语言至少大多数人能看懂了,但是任然很底层。如果你想在纯硬件上运行一个Nginx,其实是可以实现的,要么使用机器语言编写Nginx,要么使用汇编语言编写Nginx。以后呢,如何发布网页?如何添加图片,对于通篇的机器语言,能完成格式控制的人微乎其微,维护成本太高了,即便说你拥有这个能力,但其中也有一个无法避免的问题,就是这个程序局限性太高,它只能运行在某个厂商硬件的调用接口上,因为想运行在B厂商的硬件上,还需要从新学B的硬件调用接口。既然硬件级别不好编写程序,那么我们就去内核级别看看。
- 内核:内核在硬件级别之上,它将底层的硬件差异抹平了,可以把他理解为一个翻译,底层的不同硬件理解为不同国家。于是我想使用任何功能只需要和翻译交流就行了,由翻译去·调用底层的真实硬件。具体硬件支持哪些功能呢?就要由这个翻译提前准备好,等待程序前来调用,这些封装好并提供给用户调用的接口,我们就称为系统库(system call),但是翻译多了,也面临同样的问题,第一,各操作系统system call调用逻辑不同,第二,system call任然比较底层。
- 库:为解决系统调用过于底层的问题,于是它就再次将系统调用封装,向上再抽象一层,输出库调用接口。类似现实生活中的牛奶和奶牛,系统调用为奶牛,如果你想喝牛奶,你还需要自己去挤,而库调用直接就是牛奶。库调用不是必须的,有些牛人依旧可以面对系统调用来写程序,而且基于系统调用写的程序效率要更好,但是话说回来,写大型程序所需要的周期就会变长,库调用依然面临着调用方式不统一的问题,于是就出现了一个组织,它对于库的标准定义了一个规范,叫做POSIX规范(Portable Operating System可移植操作系统规范,后面的IX完全就是为了致敬Linux、Unix故意加上的),从而,使得写程序又进一步简化了。
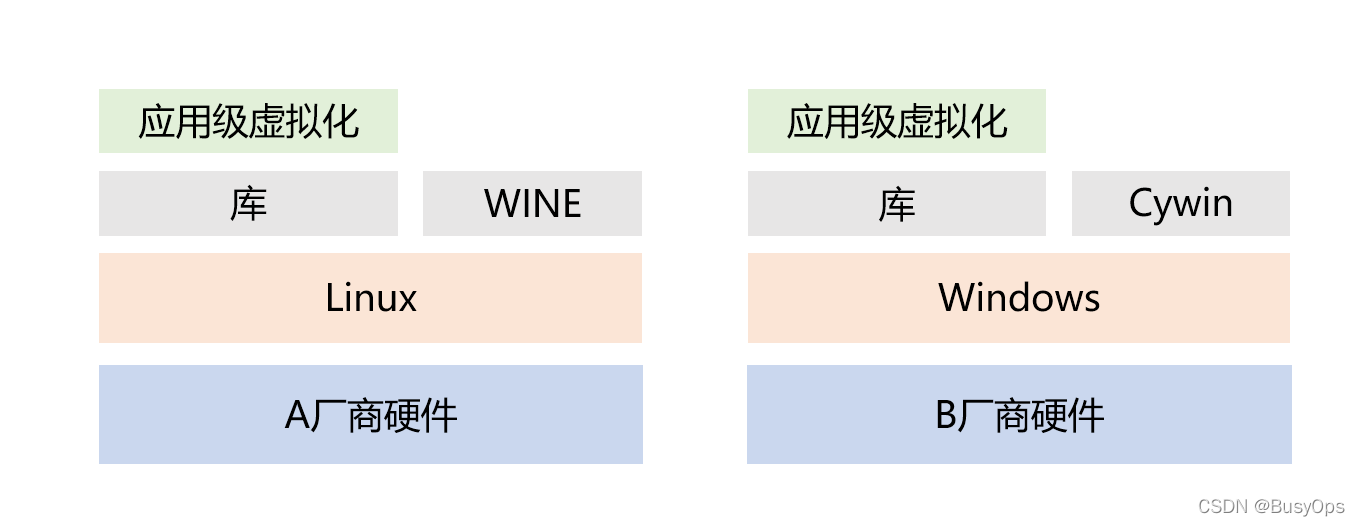
- 应用级虚拟化:既然库调用这么好,为什么还要有应用级虚拟化呢,因为使用库调用写的程序,必须精心编排它的程序逻辑,比如内存,运行程序前需要申请内存,运行完成后需要释放内存,这些都让人为来操作的话,就会带来很大的误操作风险,于是诞生了应用级虚拟化,大多数被称为解释器或者虚拟机的东西,这样就有省了很多步骤,还用内存举例,只用关心申请内存,而内存回收工作由虚拟机自动完成。并且它还有一个优点,就是他自己是一个虚拟机,不用考虑程序运行时的ABI不同的问题。
上述的层次仅解决的编程的难易程度(除应用级虚拟化外),换句话说这仅仅是从程序员的角度考虑的,但程序要想运行必须是二进制格式的,这就要从程序运行的角度考虑了。程序运行必须是二进制格式的,也就是必须从文本格式源码转换为目标平台的二进制代码。没转换前,没问题,拿着源码在哪里编译都可以,但一旦要运行,编译之后,那编译后的机器语言也仅仅适用于目标平台了。导致这种结果是因为他们的ABI不同,而程序员面对的编程接口叫API。
- WINE/Cywin:它的功用就是解决Windows和Linux的ABI不同诞生的,使得编译后的程序也可以跨平台运行。比如有个程序A,只提供了Windows版本,但你又想在Linux平台上运行,厂商又不可能提供源码,这就可以在Linux上装一个WINE,它可以模拟Windows库调用接口、路径搜索等功能。
2.编译安装的三步骤
./configure
通过选项传递参数,指定启用特性、安装路径等,执行时会参考用户指定及Makefile.in生成makefile文件
检查依赖的外部环境make:根据makefile文件,构建应用程序make install:
五、 关于库的一些命令
- 查看二进制程序所依赖的库文件
使用命令ldd /PATH/TO/BINARY_FILE - 管理及查看本机装载的库文件
使用命令ldconfig -p查看本机内存所装载的库文件
使用命令ldconf重新生成缓存 - 配置文件
/etc/ld.so.conf
/etc/ld.so.conf.d/*.conf - 缓存文件:
/etc/ld.so.cache
 某信
某信 某付宝
某付宝